“Tracking” ohne Cookies?
In diesem Artikel geht es darum aufzuzeigen, welche Akteure potentiell unsere Websiten-Besuche auswerten können, ohne bekannte Tracking-Mechanismen wie Cookies und Scripts einzusetzen. Ein Blick auf grosse Websites zeigt, dass Inhalte von vielen verschiedenen CDN, Partnern usw. ausgeliefert wird.
Mit einem Python Script lassen sich diese Zugriffe Site-übergreifend relativ einfach auswerten.
Idee
Dazu benötigen wir zwei Technologien:
- Einen Web Browser, welcher die Analyse von Traffic unterstützt und die Möglichkeit bietet, Aufzeichnungen im HAR Format zu machen
- Die freundliche Schlange aka. Python 🙂
HAR
HAR ist ein Akronym für “HTTP Archive”. Darin werden HTTP Transaktionen in einem standardisierten Format gespeichert.
In Chromium/Chrome können wir die Transaktionen unter ⇒ Developer Tools ⇒ Network anlegen, erkunden und als HAR Datei speichern.
Eine ausführlichere Beschreibung, wie man in den verbeitetsten Browsern eine HAR Datei anlegt, habe ich auf support.zendesk.com gefunden.
Ablauf
- Browser oder neuen Tab öffnen
- Developer tools ⇒ network öffnen (“DevTools” Fenster)
- Im Browser eine Seite aufrufen
- im DevTools Fenster rechte Maustaste drücken und “save all as HAR with content” auswählen
- Das Python Script mit der HAR Datei füttern
Python Script vorbereiten
Python läuft auf allen gängigen OS und kommt meistens mit einem Bündel an vorinstallierten Bibliotheken. Unser Script benötigt insbesondere:
- die urllib (urllib3)
- die haralyzer lib
Wenn diese noch nicht auf deinem System installiert sind, kannst du das mit dem Python Installer (pip) nachholen.
Python bietet uns ab Version 3.3 die Möglichkeit, ein sogenanntes virtual environment (venv) einzurichten. Bibliotheken können dann innerhalb des venv installiert werden, und nach Abschluss von Tests können wir das venv wieder löschen und werden elegant alle Abhängikeiten wieder los.
# venv vorbereiten python3 -m venv har-test cd har-test source bin/activate # jetzt befinden wir uns im venv # Bibliotheken ins venv installieren pip install urllib3 haralyzer # Script runterladen .. wget -S https://gitlab.com/tmatt/pythonscripts/-/raw/master/content.py?inline=false -O content.py # .. und im venv ausführen python3 content.py
Das Script content.py ist in meinem gitlab Repository abgelegt.
Aufgerufen wird es mit beliebig vielen Argumenten, welche HAR Dateien sein müssen, also z.B.
python3 content.py mein.har ../Downloads/nochein.har
Zugriffe analysieren
Wenn wir verschiedene Websites analysieren sehen wir schnell, dass die grossen Werbenetzwerke sich ein ziemlich gutes Bild von meinem Surfverhalten machen können. Welche Daten kommen da zusammen?
HTTP Referrer
Im HTTP Request übermitteln Browser normalerweise das Feld referrer. Esteilt dem Server mit, auf welcher Seite der Inhalt eingebettet ist.
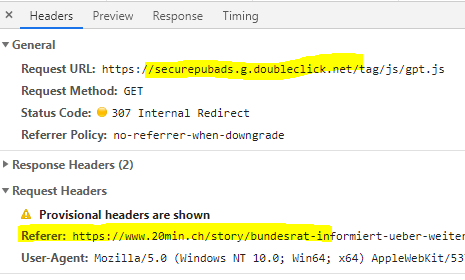
Durch die Aggregation dieser Aufrufe kann das Surf-Verhalten nachvollzogen werden. Ausserdem gibt es einige Tricks wie das Vermeiden von Caching und natürlich Cookies, welche es dem Werbenetzwerk erleichtert Benutzer zu tracken, und das auch übergreifend über mehrere Websites, mehrere Tage usw.
Weitere Header
Interessant ist auch der User Agent Header, und vor allem im Zusammenhang mit Aggregation das Do-Not-Track (DNT) Feld. Letzteres zeigt an, ob du als Benutzer (nicht) wünschst, dass Daten über dich gesammelt werden, um beispielsweise personalisierte Werbung auszuliefern.
DNT scheint im Kontext der DSGVO wieder eine stärkere Bedeutung zu haben. Der Artikel in Wikipedia deutet an, dass das Anzeigen von DNT den Empfänger verpflichtet sich entsprechend zu verhalten.
Andrerseits ist die Mozilla Foundation der Auffassung, dass dieser Header veraltet ist.
Beispiel
Blick, 20 Minuten und Tagesanzeiger gehören in der Schweiz zu den beliebtesten Websites. Drum habe ich sie mal ganz ohne Adblock (uBlock) besucht, einfach nur die Startseite geladen und von dieser das HAR File gezogen.
Damit habe ich content.py gefüttert, welches mir schliesslich diese Tabelle liefert. (Die Spaltenüberschriften sind etwas “verschoben”, da der Trenner jeweils 1 Tab ist.)
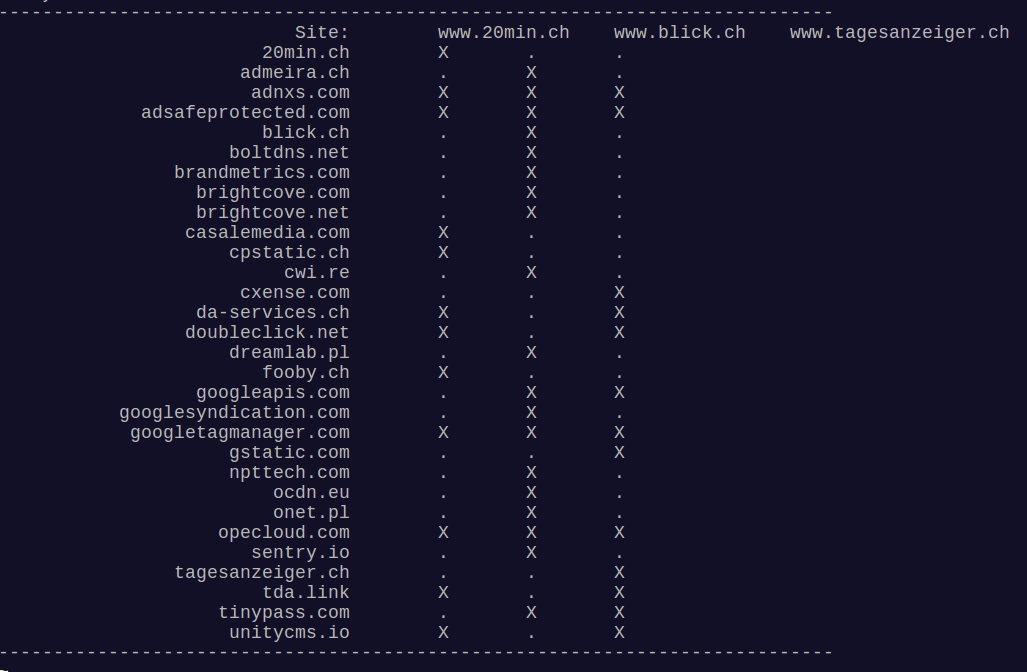
Bei meinem Aufruf sehe ich, dass alle 3 Content von adnxs, adsafeprotected, google und opencloud einbinden:

Massnahmen
Diesem Tracking sind wir mehr oder weniger ausgeliefert, vor allem auf mobilen Geräten. Auf einem PC ist es recht einfach, Tracking und Ads etwas einzudämmen. Ich habe sehr lange NoScript verwendet, bin aber mittlerweile bei ublock origin gelandet. Diese Browser-Erweiterungen unterdrücken viele Anfragen zu Werbenetzwerken, ohne dass die Funktionalität von Websiten gross darunter leidet. Im “schlimmsten Fall” kann man die Erweiterung für eine bestimmte Website temporär oder dauerhaft abschalten.
Bei den Smartphones ist es leider nicht so einfach, da die dort vorinstallierten oder erhältlichen Browser keine Extensions unterstützen. Es gibt Tricks mit VPNs oder entsprechende Browser für gerootete Geräte; diese Techniken sind aber für viele Benutzer aber zu komplex und fehleranfällig.
Zusammenfassung
Für mich war es spannend, mit einem Python Programm etwas mehr über HAR, Browser, HTTP Header, Werbenetzwerke/CDN und Tracking zu erfahren.
Updates
19.9.21: Verschiedene Ergänzungen eingepflegt, insbesondere zu Python venv, sowie Screen Shots.
12.3.24: Aufruf des content.py Script präzisiert.